(二)测算方法
1、数据源与数据预处理方法
五通指数各指标所用数据源具有权威、可靠、客观、统计口径一致的特征。本报告所使用的量化数据主要来自:世界银行、国际货币基金组织、Web of Science数据库、国家统计局、外交部、商务部、财政部、证监会、中国人民银行等;以及部分国内外权威研究报告或年鉴,如:中国海关统计年鉴、中国贸易外经统计年鉴、全球营商环境报告等。部分数据通过大数据技术与方法分析相关互联网数据得到。
数据预处理是对数据进行分析与挖掘的前提,所使用的主要方法有数据的清理、集成、空缺值填充、选择、变换、归约等。对正向指标主要采用了最小-最大规范化、极大值规范化等方法,对负向指标主要采用非线性规范化方法。
最小-最大规范化方法,将原始的数据进行线性变换,使其映射到某一个新的区间中,如[0,1],[0.3,1],[a,b](a<b)等。具体计算方法如公式1所示。公式1将该指标数据集中的所有数据映射到区间[a,b](a<b)内。
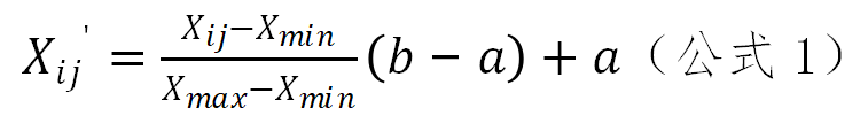
极大值规范化方法,它用原始数据除以该数据列的极大值,具体计算如公式2所示。公式2将该指标数据集中的数据映射为最大值为1、最小值未知的数据列。
常见的适用于负向指标的一种非线性规范化方法,是用该数据列的极小值除以原始数据,具体计算如公式3所示。公式3将该指标数据集中的数据映射为最大值为1,最小值未知的数据列。
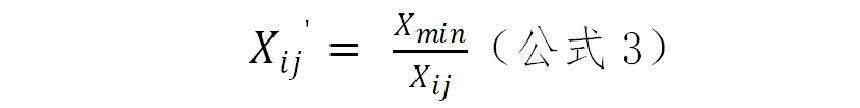
名次序数的标准化采用名词序数百分比化方法,即将数据对象的名次序数转化为在百分比内的相对位置,是将逆向定性指标转化为正向定量指标的一种方法。具体计算方法是:先对数据对象排列名次,得到名次序数,然后利用公式4计算名次百分,具体计算如公式4所示。

Xij表示数据对象的名次,n是全部数据对象的数量。用(Xij-0.5)处理可以避免出现最后一名的名次百分比为0的情况,各不同的名次均匀地分布在百分位中,名次越高,百分比越大。
聚类分析是对数据对象进行划分的一种过程,它将数据对象分组成多个类或簇,使得在同一个簇中的个体具有较高的相似度,而不同簇中的个体差别较大。本报告综合使用了k-means和层次聚类方法。
2、指标赋权与结果综合方法
五通指数设定总评分为100分,对5个一级指标——政策沟通、设施联通、贸易畅通、资金融通、民心相通赋予相同的权值,均为20分,对每一“通”的二级和三级指标分别赋予相应的权重。
综合评价模型可把评价对象的多个指标的取值合成为一个综合数值。本报告采用加法综合评价模型,即:对各指标的评价值进行加权算数平均,求综合评价值,具体如公式5所示。
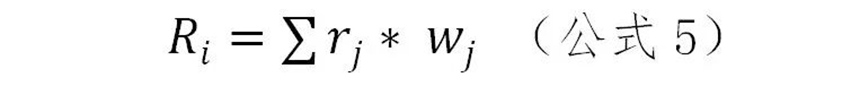
其中,Ri为第i个国家的综合得分,Wj为第j个指标的权重,Rj为第j个指标的得分,它是经过数据规范化处理后的某一评价指标的具体取值。在五通指数指标体系中各指标的具体取值都做了指标的正向化转化,综合评价值越高,其互联互通程度越好。
(三)测算对象
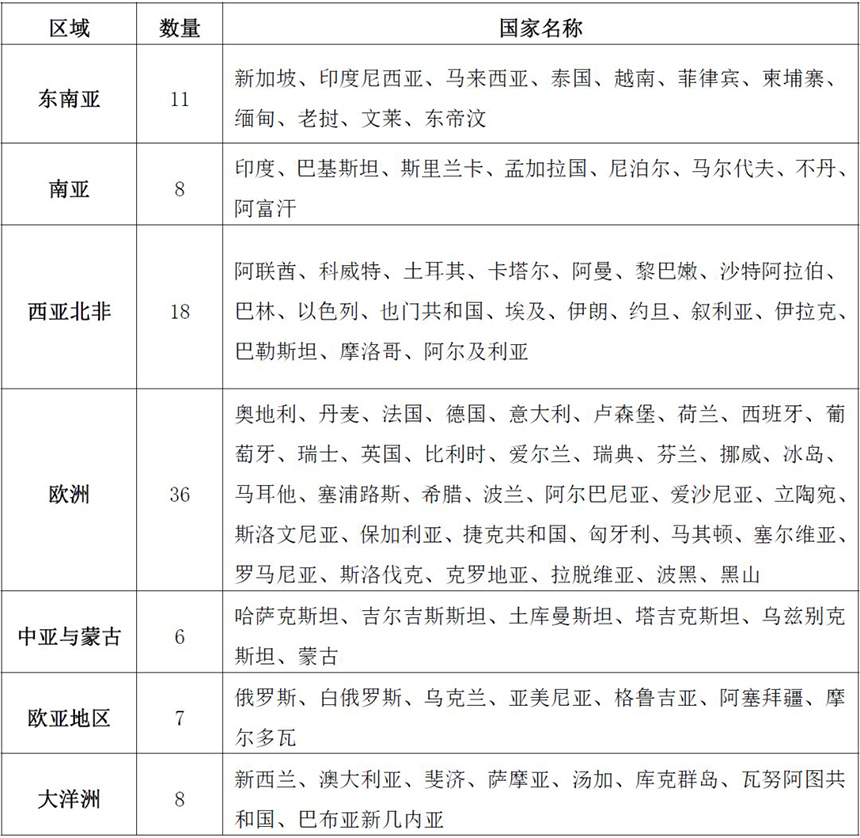
本轮测算中,课题组在“一带一路”建设初期涉及的64个国家的基础上,将更多与我国签署“一带一路”合作谅解备忘录等文件的国家纳入在内,最终测算了94个国家,其区域分布如表2-3所示。
表 2-3 “一带一路”沿线94个国家的区域分布